Abstract
Hand gestures are a natural means of interaction in Augmented Reality and Virtual Reality (AR/VR) applications. Recently, there has been an increased focus on removing the dependence of accurate hand gesture recognition on complex sensor setup found in expensive proprietary devices such as the Microsoft HoloLens, Daqri and Meta Glasses. Most such solutions either rely on multi-modal sensor data or deep neural networks that can benefit greatly from abundance of labelled data. Datasets are an integral part of any deep learning based research. They have been the principal reason for the substantial progress in this field, both, in terms of providing enough data for the training of these models, and, for benchmarking competing algorithms. However, it is becoming increasingly difficult to generate enough labelled data for complex tasks such as hand gesture recognition.
The Idea
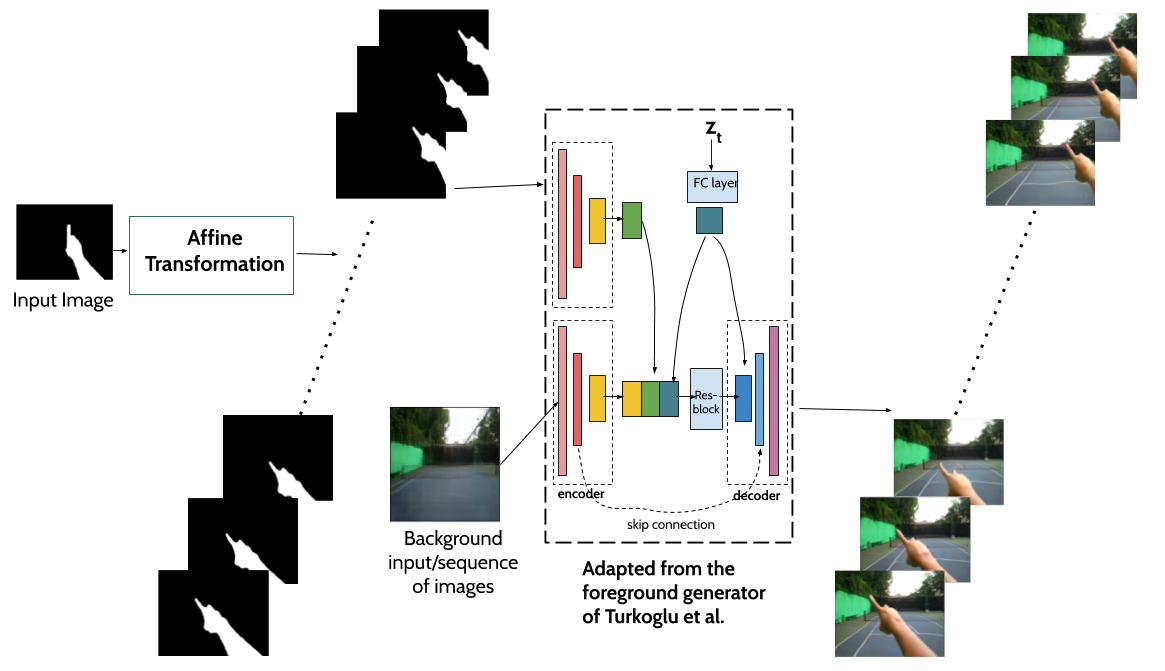
In this work, we propose a neural network architecture that is capable of generating a sequence of video frames given an input mask layout. These masks passed in succession to the generator network results in a video sequence with given background image. We can even use different video frames as input (passed successively) for the background. This results in videos with both static and dynamic backgrounds.
Framework

We used the ability of the model outlined by Turkogluet al. to generate video sequences with different backgrounds but same (or controlled) fingertip and hand as in the reference input image. The proposed framework sequentially composes a scene, breaking down the underlying problem into foreground and background separately. Our approach utilises the foreground generator as proposed by Turkoglu et al. to superimpose elements over the given background. Such a network allows us to control various properties, including fingertip location, as well as hand’s shape and appearance.
Results
-
Using CycleGAN

-
Synthesised using our approach.

Clearly, images are more clearer and the segmentation masks give us control over the fingertip location, hand's appearance, shape, size and so on.
Gestures
Our approach gives us the capability to generate a very large synthetic egocentric gesture pointing dataset. A few examples are shown below:
-
A circle pointing gesture

-
A square pointing gesture
